ACKNOWLEDGEMENTS
Thanks to George Marsaglia for inventing the multiply-with-carry pseudorandom number generator.
SOURCE CODE
If you want to cut to the chase, the C source code for GetLMD is here and for the hashes alone is here.
INTRODUCTION
Because error checking and correction algorithms reside at multiple levels of the software and hardware stack, they can consume significant amounts of power, and more importantly, increase latency. The extent of this problem may become more apparent as the number of bits in world continues to increase exponentially. LMD offers some relief.
In order to prevent a 2-bit error from going undetected, we need to find the longest possible subseuqence of the iterator which produces unique shiftoids. The best such candidate I found resulted in the value of (x0, c0) given above. In particular, it guarantees that y is immune to 2-bit errors occurring in the first 224,915 DWORDs (892,454 bytes). This is within the longest 1% of such sequences. This length provides plenty of space for, say, a 512KiB solid state disk sector plus its ECC and metadata. Since most messages which use EDCs in the world are less than this length, LMD provides more protection against 2-bit errors than might be the case, had the seeds been chosen at random. It's desirable to avoid "what if" scenarios regarding events whose probability appears to be small, but might not be. The selected seeds provide some such comfort.


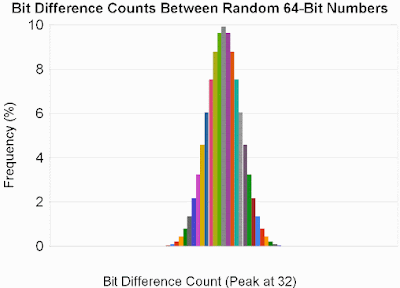


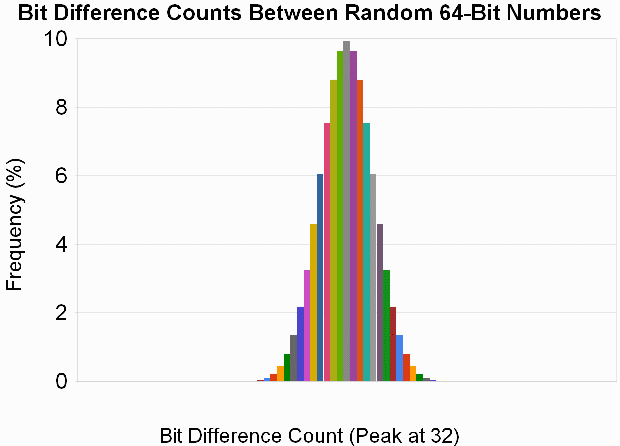
Protective Capacity
The guts of the LMD is a multiply-with-carry (MWC) iterator. It produces one DWORD (32-bit) value on each iteration, which is for all practical purposes statistically unbiased. Although there are only 2^32 unique 32-bit values, the generator keeps another DWORD stashed away behind the scenes. This affords it a period of 4,611,684,809,394,094,079 (just under 2^62). Multiplying by the size of a DWORD, we get almost 2^64, meaning that the cycle is big enough to cover any data that might be used in a 64-bit computing environment, without succumbing to the hazards of periodic behavior that can doom an error detection algorithm. As discussed in the Theory section, LMD appears to be sufficiently reliable at detecting errors in both random and highly uniform messages (strings), for use with 64-bit address spaces.
Security
LMD is insecure by design, but could easily be made so by use of encryption. This would defeat the purpose of fast error detection, and is beyond the scope of this paper. (A hacker can simly modify the LMD to match his modified data.)
For the impatient, I will describe the algorithm now. A detailed explanation of the theory will follow.
ALGORITHM
All arithmetic operations herein are unsigned.
Iteration
The iterator simply takes a DWORD pair, (x, c), and iterates it to produce a new (x, c) until, well, the sun burns out. The recurrences are as follows, in terms of an intermediate 64-bit product, p:
ITERATE_NO_ZERO_CHECK means:
p = 0x7FFFFDCD * x + c
x <- p MOD 2^32
c <- p / 2^32 (Shift p right by 32.)
ITERATE means:
do {
ITERATE_NO_ZERO_CHECK
} while(x == 0)
where:
(x, c) starts as (0x26711AAF, 0x7B98D2B0), which is then iterated once in order to produce the first x value for use; the seeds are not used directly.
Here are the first few values. x is the output; c is just used to prevent periodicity in x:
(x1, c1) = (0x70DB23D3, 0x13388D03)
(x2, c2) = (0x6148C3FA, 0x386D90F1)
(x3, c3) = (0x45669223, 0x30A46127)
(x4, c4) = (0x1010FE2E, 0x22B34879)
(x5, c5) = (0xCD54494F, 0x08087EF3)
(x6, c6) = (0xF7AB4636, 0x66AA22E3)
(x7, c7) = (0xB8FEBA21, 0x7BD5A0FA)
(x8, c8) = (0x23A24A67, 0x5C7F5B7A)
(x9, c9) = (0x7E95BAF5, 0x11D124E5)
Thus after evaluating the linear combination of x and c, the low DWORD becomes a new x, and the high DWORD becomes a new c. Spit out x as the next pseudorandom value. Reapeat as necessary. If x comes out as 0, then reiterate. (Fortunately, the first 3,132,319,170 iterations do not yield 0.)
Seed Selection
The numbers 0x7FFFFDCD, 0x26711AAF, and 0x7B98D2B0 were not randomly selected. Suffice to say at the moment that they have certain properties which enhance the error detection capability of LMD. More on this in the Theory section.
(Parallel) Dot Product
Each successive x is multipled by corresponding DWORDs in the message, then added to an accumulating sum called a "partial digest", y. In vector terms, then, y is a dot product of the message, (d0, d1, d2...) with the outputs of the iterator (x1, x2, x3...) - x0 having been the orignal seed, which is not combined with the data:
y = (x1 * d0 + x2 * d1 + x3 * d2... x(n + 1) * d(n)) MOD 2^64
If you have many processors (or SIMD pipes within a processor) working on the same digest at the same time, then they can each generate a smaller partial digest, the sum of which being y.
This is what makes LMD parallizable. Because the data is not fed back into the iterator (as it is in CRC), many processors can work on separate pieces of a long packet, eventually unifying their work by adding their partial digests to y.
Normally, however, such parallel behavior weakens the resultant EDC. In other words, due to the lack of feedback on the EDC, 1-bit errors in the message tend to create only few-bit errors in the digest, for which a noisy communication channel might compensate by corrupting the EDC itself, thereby creating the illusion of good data, when it is actually bad. LMD avoids this by performing entropy amplification on the partial digest before the (final) digest is issued.
Entropy Amplification (Digest Finalization)
Feedback is what makes CRC fairly robust, but it costs a lot of time because it is serialized down to the level of a single message bit, which is somewhat optimizable with heroic tricks. Some attempts have also been made to accelerate the process in hardware, for example Intel's recent creation of the CRC32 instruction, but such accelerations lack the flexibility that software-defined algorithms possess, particularly if longer EDCs are required or better seeds are discovered. Unlike LMD, CRC also maps inefficiently to the instruction sets of most cheap microprocessors.
Furthermore, the feedback mechanism employed by CRC makes periodic error compensation analysis much more difficult, as it possible that patterns in the message itself may render the protection afforded by the CRC, weaker. LMD is not very susceptible to this problem, as its iterator proceeds the same regardless of the message content. Only at the final step do we integrate the partial digest into the iterator.
Thus the LMD approach can be much faster: we can evaluate the cummulative partial digest in parallel, then do a few feedback iterations just before we issue the (final) digest. (Care must be taken to ensure that each partial digest is evaluated starting from the correct (x, c) value.) This entropy amplification process causes 1-bit errors in the message to yield about 32 bit inversions in the digest, vs. only about 18 in the absence thereof. 32 is in fact optimal; further feedback will not achieve meaningfully higher entropy. The following sequence accomplishes this feat:
(Finish computing dot product, y, above, leaving (x, c) as its most recent value, such that x has been used to compute the last term of y.)
z = (y + (c * 2^32) + x) MOD 2^64
x <- z MOD 2^32
c <- z / 2^32
ITERATE_NO_ZERO_CHECK
ITERATE_NO_ZERO_CHECK
ITERATE_NO_ZERO_CHECK
z = (z + (c * 2^32) + x) MOD 2^64
z is the (final) digest. Done!
Do not save the iterator state for use later, as the integration of message data into (x, c) may have caused the latter to become (0, 0), which would hang the system on the next ITERATE.
Example: the digest of the DWORD message:
{0x12345678, 0x87654321, 0xFFFFFFFF, 0, 0x80000000}
is 0xFB71C5BB9378B781.
The digest of a null message is 0xAC3D33D76BD7ACD2. This is just the result of sending the iterator seeds, and a partial digest of 0, directly into the entropy amplification stage.
THEORY
Long-Period Iterator
The ideal EDC should be capable of detecting a wide variety of errors, even if they display periodicity (like bit 0 being broken on a memory bus) or rarity (like a 1 in a field of a million zeroes). In short, there must be a negligible probability, even under optimally unfavorable noise conditions, that accidental alterations to the digest will make it work out correctly for an erroneous payload. No popular message error mode case should be an exception to this requirement.
The MWC generator at the heart of LMD has period 4,611,684,809,394,094,079. This stems from the fact that we have:
a = 0x7FFFFDCD (the coefficient of x) and
b = 2^32 (the base by which is x is extracted as a modulo remainder)
and both:
ab - 1 = 9,223,369,618,788,188,159 and
(ab - 1) / 2 = 4,611,684,809,394,094,079
are prime, i.e. ab - 1 is a "safe prime".
According to the Wikipedia article linked above, this implies that the period is the value given above. I verified this computationally for similar 16-bit generators, and it appears to be correct. The lack of periodicity in LMD - at least, for all practical purposes - fulfills one of the key requirements set out above.
Bit Lane Fairness
Without going into detail, as it has been covered extensively elsewhere, MWC generators which employ safe-prime coefficients are very fair in their distributions. In other words, x looks like noise. Complementary-multiply-with-carry (CMWC) generators are allegedly perfectly fair with respect to the number of 0s and 1s that appear in each of the 32 bit lanes over the cycle length. However, they take more computation time, and the improvement in fairness over MWC appears to be trivial. So plain vanilla MWC is unlikely to protect any bit position much worse than any other, if applied fairly. Multiplication (in the computation of the subproducts of y) reasonably fulfills this requirement, because if any bit of the message is inverted, then the product will on average be different by roughly the same number of bits, regardless of the lane in which the error occurred.
Autocorrelation (Discrete Spectral) Analysis
Over millions of different bit phases and periods, I was unable to detect any significant autocorrelation in the individual bits of the x values output from the LMD iterator. At worst, subsequent bits at a given phase and period were as much as 54.3%, or as little as 45.5%, likely to be correlated (equal), which appears to persist regardless of the number of samples. Nevertheless, based on subsequent other statistical analysis presented below, I think this modest bias is acceptable as-is. And all 32 correlation levels of bit n in DWORDs m and (m + 1) were within 0.003% of 50% after 2G trials.
Checking for (x = 0)
Obviously x must not be 0. Otherwise the product p would be oblivious to the content of the DWORD in the position corresponding to (x = 0). We take care of this by pointing out that the particular generator in question produces 3,132,319,170 nonzero values before producing a zero, excluding the initial seeds. Thus in most cases - and all 32-bit address spaces - there is no need to waste time testing for this condition. For longer messages, testing could commence after this many iterations, or a data table of iteration ordinals which produce 0 could be used, to the extent that the locations of such ordinals are precomputable.
2-Bit Error Protection and Shiftoid Analysis
Because x is never 0, it should be clear that if any 1 bit error were to appear in the message, it would change the partial digest, y, to y', such that (y != y') in every case. Statistically speaking, there is less than 1 chance in 2^62 (and possibly close to 1 in 2^64) that z(y) = z(y'). In other words, if the partial digest changes, then for all practical purposes, we can assume that the (final) digest will change.
Thus, effectively, we have 100% protection against 1-bit errors. Why does this matter?
If errors were extremely common, then you wouldn't bother employing an EDC, as you would know that you will need to repair the data almost all the time; you would employ an ECC directly. So this implies that in most cases, your data is error-free.
So if 1-bit errors are rare, then 1-bit errors must be exponentially more common then 2-bit errors; 2-bit errors must be exponentially more common than 3-bit errors; etc. So by eliminating the possibility of 1-bit errors going undetected (above), we have will have eliminated most of the possibility that a bad message might evaluate to a correct LMD.
2-bit errors are the next most-probable case. Beyond 2 bits, the constraints get so extensive that it is no longer feasible to tune the LMD's (x0, c0) so as to minimize the occurrence of such higher-order bit errors. But it hardly matters, because more-than-2-bit errors are extremely rare and detected with near-theoretical-maximum efficiency (1 in 2^64 odds of failure) anyway.
So how can we prevent 2-bit errors from being undetected? First, let's assume that both errors occur in the message, and not the digest itself. (Entropy amplification of the partial digest, and the length of an average message in the real world, imply that the probability of a 1-bit digest error compensating for a 1-bit message error is negligible relative to all the ways in which we might have 2 mutually compensatory errors in the message.)
To answer this question, first think about what a 1-bit error really means. Our subproducts of y look like this:
x(n + 1) * d(n)
x(n + 1) is just a random 32-bit value. If bit b of d(n) is 1 where it should have been 0, then the product above will increse by (2^b)x(n+1). If the opposite occurs, then the product will be reduced by the same.
With only a single error, then, the effect on y is always nonzero. But with 2 errors, it's possible that we will add (2^b)x(n+1) to one subproduct, then subtract it from another. Convince yourself that this can happen only if x(n + 1) and (some other) x share a common shiftoid, that is:
Given:
x = 2^u * v
where u is the maximum possible integer that allows v to be an integer. Then v is the shiftoid of x.
Examples of shiftoids in binary:
111001 is the shiftoid of 11100010, 1110001000, and 1110001000000.
10011 is the shiftoid of 10011, 100110, and 10011000.
If the 2-bit error is that both bits are erroneously 0 or 1, then there is no way that they can leave the partial digest in the same state, because the sum of 2 values of the form (2^n * x, x > 0, 0 <= n <= 31) is always greater than 0, but less than 2^64. Therefore, for all practical purposes, such errors will be caught with 100% efficiency. (Yes, there might be a trivially rare case in which different partial digests map to the same digest.) So we are only concerned with 2-bit errors in which a 0 trades places with a 1.
Probability of Bad Messages Going Undetected
In the case of any EDC, "failure" means that a message is discovered whose digest evaluates correctly, but which has been altered since the EDC was generated. (It's much rarer, but possible, that the message is good, but the EDC is corrupt, in which case good data is falsely labelled bad. But in this case, the message would usually simply be or recovered from a backup, so I don't consider it a failure.) In the real world, bits spontaneously flip with the passage of time - eventually 50% of them, which represents maximum entropy. How well an EDC copes with this aging process is a key measure of its worth.
The trouble is that the probability of EDC failure depends upon the error rate in the message, the distribution of message lengths, the error rate in the digest, and usually, the message content. Therefore, it is difficult to directly assess the robustness of an EDC; we simply don't know what data it will be utilized to protect. Worst-case scenarios are analyzable, but don't reflect reality and thus could underrate a strong EDC. Fortunately, absent a room full of quantum computers, there are a few landmarks which can assist us with such an assessment of LMD.
First of all, LMD's bit lane fairness is a good sign. It shows that if there is some bias to LMD, then it does not likely occur in a manner which would resonate with the common failure mode in which a given hardware bitlane tends to stick to one state or the other. Secondly, the phase and period analysis suggests that no meaningful resonance will occur with the data, either - even if its best autocorrelation occurs at unusual integer multiples of bits. But we've discussed this above.
Fundamentally, it's important that LMD can actually produce all possible 64-bit integers as digests, so long as the message consists of at least (something like 4) DWORDs. As the message length increases, the distribution of possible digests appears to flatten out, so that in the infinitely-long-message limit, each possible digest is equally represented in the space of all possible n-DWORD messages. This matters because it means that we minimize the probability of digest collision, in which multiple messages share the same digest. (Collisions are clearly inevitable beyond 2 DWORDs).
We also want assurance that minimal changes to the message will alter the digest radically. Otherwise, the digest might work out correctly despite the message being wrong. Or, a not-so-rare 1-bit error to the digest itself might flip it back into looking correct. Ideally, when a 1-bit error occurs in the message, we want the digest to change as though it were selected at random.
To assess the quality of LMD's response to such trivial message alterations, I looked at 3 hard cases, and sampled results over 2G trials each.
The case first involved random messages of linearly increasing length, in which I flipped a bit at random, and looked at the ensuing number of bit differences between the digests. Thus trial n looked at an n-DWORD message in which 1 bit was flipped. The results, shown below, compare well to what we would expect if the digest were changed at random simultaneous with the bit flip, with the average number of differences being 31.97 bits (vs. an optimum of 32).


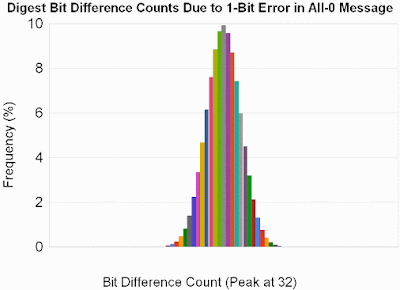
The second case was exactly the same, except that I set single bits in all-0 messages of linearly increasing length. The results were essentially identical, with an average bit difference count of 31.94:

The third and final test was just like the second, except that I cleared single bits within all-0xFFFFFFFF messages. The result is unexpectedly good protection, with an average of 31.99 bit differences. I have a hunch that this is related to the reason for which CMWC is shows less bias than MWC.


As you might expect, the two distributions gradually converge as the number of (ITERATE_NO_ZERO_CHECK)s in the entropy amplification stage increases. But the distributions above are already so close to random that I don't think a 4th iteration is worth the additional latency. Any fewer iterations, and the peak moves to the left of 32, which I find unsatisfactory.
The combination of bit lane fairness, autocorrelation, unique-shiftoid sequence length, and single-bit-toggle test results demonstrate the strength of LMD, to the extent practical with my very limited computing resources. I hope that you'll find it useful.
FUTURE ADAPTATIONS
In principle, LMD would be improved by finding a subsequence of the iterator which produces more than 224,915 unique shiftoids in a row, but I believe such is a game of diminishing returns, as beyond this threshold, 2-bit errors are still astronomically unlikely to go undetected.
You might argue that with the fantastic density of information coming online at an exponential rate, a 128-bit version of LMD would be the next logical step. At the moment, I disagree. Considering how much energy expenditure and latency in the world is due to error correction, it would be computational overkill; other catastrophic and nonrecoverable failures happen with frequencies much higher than the probability of LMD failing to detect a corrupted message.
FEEDBACK
If you want to discuss this, you can email me at hpkejjy@gmail.com (leave off the "h"), or just post a comment on this page.
May your errors be obvious!
Russell Leidich
Original: July 2, 2009
No comments:
Post a Comment